Smarter AI applications continue to help us daily: technologies such as voice interfaces and voice assistants are becoming increasingly ubiquitous. To democratize the innovation in this domain, the need for high quality voice data is obvious. Of course, not every company has the resources to prepare such data sets, therefore, projects such as Mozilla’s Common Voice initiative is important to help teach machines how real people speak. This is important to boost innovation & start-ups, and help make technologies such as voice recognition, text to speech generation, and speech analytics open and accessible to everyone.
Very recently, in July, 2020, Mozilla announced the mid-2020 release of their multilingual voice data set. As TM Data ICT Solutions, we were excited to see the details of this update, and being based in the Flemish Region of Belgium, we immediately wanted to see how Dutch was represented in that data set. We were very surprised to see that there wasn’t much data for Dutch! What’s even more interesting: another language, Catalan, is much better represented in this data set. For example, checking the data set size and comparing English, Dutch and Catalan, we observed that English has 50 times more data than Dutch, and even Catalan has 14 times more data than Dutch:
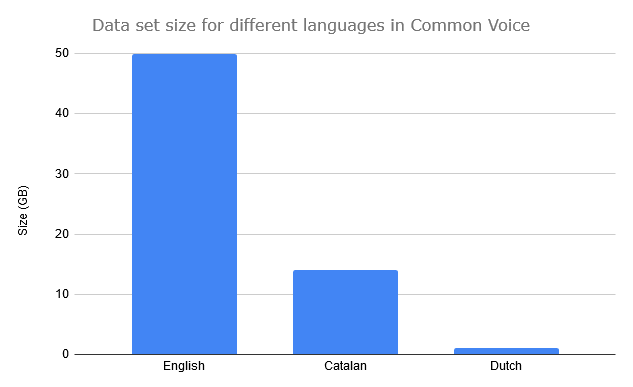
Looking at the numbers of hours of voice recordings for the same set of languages, we have seen the following:
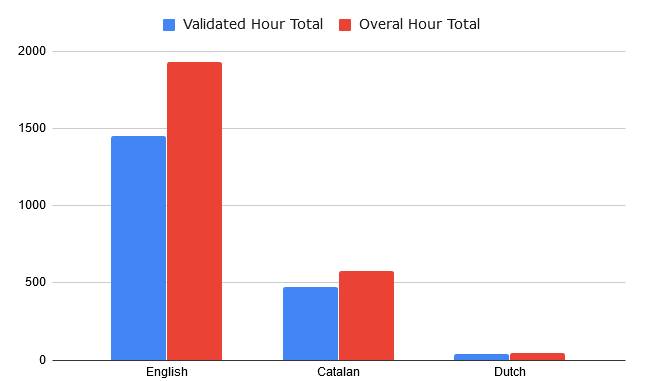
A similar discrepancy is reflected in the number of different voices: Dutch has only 889 whereas Catalan has 4872, and English has more than 60.000 voices.
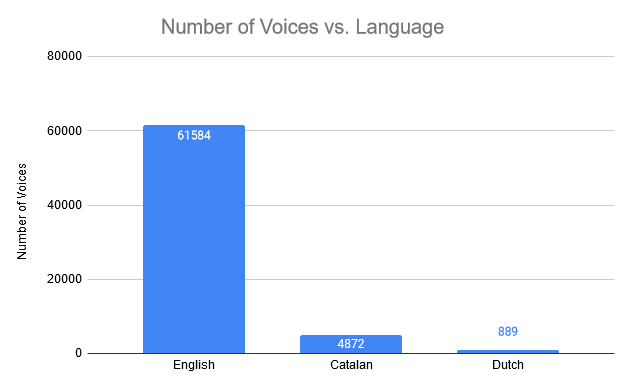
This is indeed a curious case for Dutch, a language spoken by nearly 30 million people. It’s obvious that Belgium, Flemish Region in particular, and the Netherlands must strive for a better representation in this Common Voice data set, that is, if we want better and more innovative applications for voice and speech applications in Belgium and the Netherlands, tailored to the local culture and business.
Now that a lot of infrastructure is already made available thanks to Mozilla, it is up to Dutch speakers to push things forward. If you’d like to discuss innovative ways to make this happen, you can always contact us at info@tmdata.be .
If you’re curious about applying AI-powered speech and voice technologies, independent & open source voice assistants, speech analytics, and other solutions to your projects and business, also feel free to contact us, and as TM Data ICT Solutions we’ll be happy to help you.
2 thoughts on “The curious case of Dutch in Common Voice Data Set”
Comments are closed.